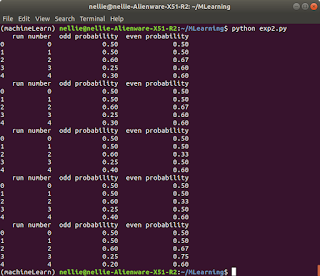
refactor Python Binary Tree

I have an older post where I posted this code, but I wanted to explain my 'delete' method in more detail. Take a look at this: [alt attribute attached] This depicts how at some point, depending on which side of a node you are on, there is a limit to how far a branch can reach. 'A' would be the Left child node of 'H', and the farthest it's right branches can reach is to 'H'. Anything more than H, is on the other child node on the right. Likewise, for child node 'Z', it's left most branches have the same limit of 'H'. Because all other smaller/lesser than keys would go on the left child node. At first I had my delete method throwing all right children onto the right branch of the left child and replacing the parent node with that modified left child. But then I realized: [alt in image] The right most branch of the right side of root has limitless potential. It is not restricted in any way by the median f...